As I’ve recently reported, the ThinkPad X12 Hybrid Tablet has two USB-C ports and no USB-A ports. Worse yet, a USB-A to USB-C adapter does not work to boot this machine, as I discovered the hard way. Compound that with FAT32’s 4 GB per-file ceiling and a install.wim that routinely tops 5 GB. That makes a straight Windows 11 ISO write impossible. Thus, I’ve worked through a repeatable solution that splits the WIM, mirrors the ISO source tree with Robocopy, stamps a proper bootable ISO with oscdimg, and finally writes it to a native USB-C drive with Rufus — no errors, no drama. It’s my way of building X12 boot media, though you can use MCT instead, if you prefer.
Manually Building X12 Boot Media. Step-By-Step
Just for grins I wanted to start from an official Windows 11 ISO, and create the boot disk from scratch. Here’s what I did:
Step 1 — Download the Windows 11 ISO
First, head to Microsoft’s official software download page at microsoft.com/software-download/windows11 and choose the “Download Windows 11 Disk Image (ISO) for x64 devices” option. Select your preferred language and grab the multi-edition ISO — it weighs in at roughly 6.5 GB, so make sure your destination drive has ample free space before you start. Save it somewhere you can easily reference in the steps that follow. I grabbed mine from the Downloads folder/library.
Step 2 — Mount the ISO and Split install.wim
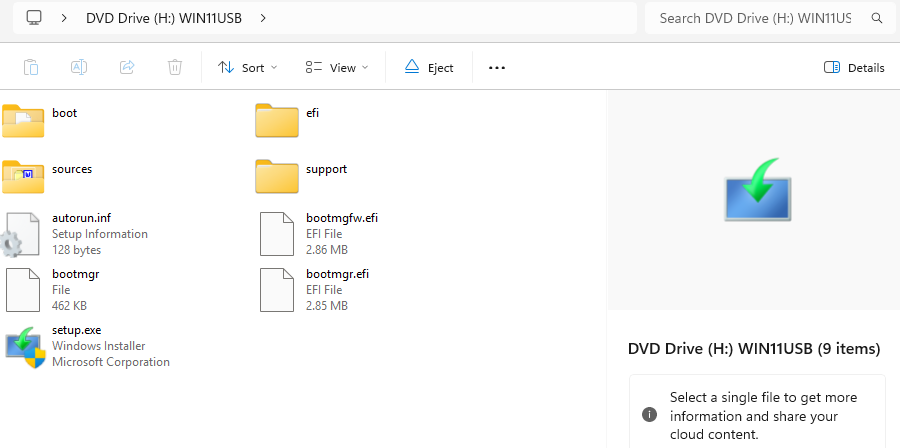
Next, mount your downloaded ISO in File Explorer by right-clicking it and choosing Mount. In response, Windows assigns it a drive letter automatically (I’ll use D:\ here, though it shows as H:\ in the lead-in screencap). Then open an elevated command prompt and use DISM to split install.wim into 3,500 MB chunks, small enough to fit safely inside FAT32’s 4GB per-file limit (if you cut’n’paste the following, it should be a one-liner at the command line):
dism /Split-Image /ImageFile:D:\sources\install.wim
/SWMFile:C:\X12Media\sources\install.swm ^ /FileSize:3500
DISM writes install.swm, install2.swm, and any additional parts directly into your target sources folder. Windows Setup picks them up automatically at install time — no extra configuration required.
Step 3 — Build the ISO Source Folder with Robocopy
Then, use Robocopy to mirror nearly all files from the mounted ISO into a clean working folder — but explicitly exclude the oversized install.wim you’ve already replaced with the split .swm files:
robocopy D:\ C:\X12Media\ /E /XF install.wim
The split .swm files you created in Step 2 are already sitting in C:\X12Media\sources\, so the result is a complete, well-formed ISO source tree ready for imaging. Everything Setup expects is present and correctly sized.
Step 4 — Generate Bootable ISO with oscdimg
Next, you need a copy of the MS Operating System CD Imaging utility, aka oscdimg.exe. You may need to install the Windows ADK (Assessment and Deployment Kit) from Microsoft if you haven’t already (oscdimg.exe ships with it). I found one inside the MiniTool Partition Wizard (MTPW), and used that version instead (worked like a charm). Wherever you get it, oscdimg.exe is the right tool for stamping a proper dual-purpose ISO. The command below targets both legacy BIOS (etfsboot.com) and UEFI (efisys.bin) boot sectors in a single pass:
oscdimg -m -o -u2 -udfver102 ^ -bootdata:2#p0,e,bC:\X12Media\boot\etfsboot.com ^ #pEF,e,bC:\X12Media\efi\microsoft\boot\efisys.bin ^ C:\X12Media C:\Output\Win11_X12.iso
The -m flag overrides the 4 GB maximum image size limit, while -u2 enables the UDF file system for broad compatibility. The resulting Win11_X12.iso in C:\Output\ is your custom X12 Hybrid boot media image.
Step 5 — Write Bootable USB Media with Rufus
Finally, download Rufus from rufus.ie and launch it as administrator. For the drive, I needed a native USB-C flash drive — I ordered a Kingston DataTraveler 70. Do not reach for a USB-A to USB-C adapter: the X12 Hybrid will not boot from one, full stop.
Select the Kingston DataTraveler 70 in Rufus, point the “Boot selection” field to Win11_X12.iso, and set the partition scheme to GPT with target system UEFI (non CSM), leaving the file system at FAT32. Rufus handles the split .swm files correctly because they are already embedded and sized within the ISO — no special Rufus settings needed. Click START, accept any warnings about erasing the drive, and within a few minutes you have fully functional X12 Hybrid boot media ready to go.
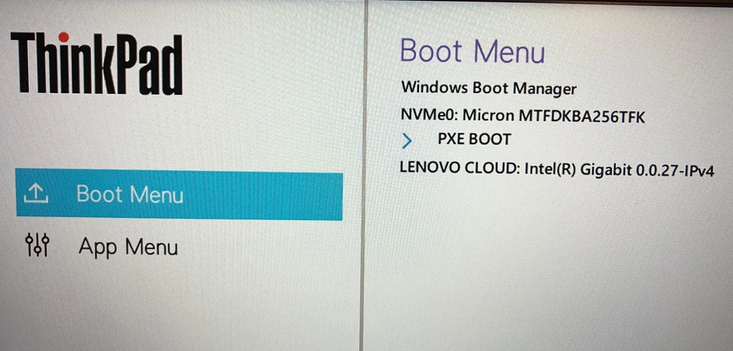
The Proof’s In the Booting…
I was relieved when the X12 finally booted from the Kingston UFD entry in the UEFI boot menu. That had been a LONG time coming. Even so, the extra steps described above add perhaps 15 minutes to a typical USB media build. That said, they reliably eliminate the frustrating “Windows cannot install required files” errors that plague direct installs on picky devices. Give this workflow a try on your X12 Hybrid — or on any device where you run into issues booting from USB media— and let me know how it goes in the comments below.
I’m glad to have the X12 back on the working roster. Indeed, I’m getting ready to upgrade it to a Beta Channel build shortly, Hopefully, I won’t need the repair/recovery media I just built. But if I do, I’ve got it handy. Here in Windows-World “better safe than sorry” are words to live by!